
Investigations of Phase-Aware Source Code
What does it look like when phase-awareness is exposed in the programming model?
Recent changes in OpenJDK’s Project CRaC have enabled new ways to express phase-aware applications. Source code can now reflect different phases and can offer new ways to group computation to make clear when operations occur.
Execution Models
A typical application runs continuously from start to end. Though there may be phases within the program, even beyond the typical startup / warmup / steady-state model, they aren’t expressed in the source code. Execution looks like a straight line.

Now, CRIU investigations such as OpenJDK’s Project CRaC and Eclipse OpenJ9’s CRIU Support project - and really all efforts to use CRIU with Java - have split that single execution into two parts: pre-checkpoint and post-restore.
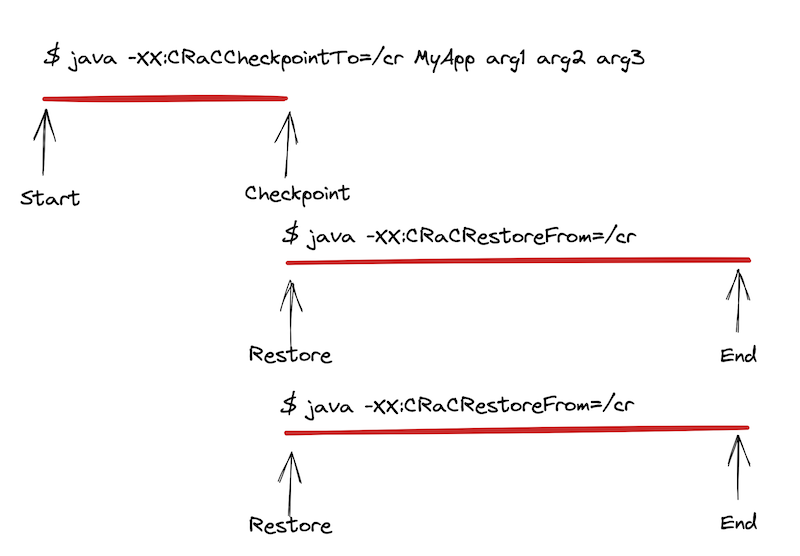
With this model, the user tries to pick a “good” point in the execution to take the checkpoint that’s late enough that sufficient initialization has occurred but early enough that not too many things will need to be fixed up. Picking the right point is still more an art than a science. And regardless of the chosen point, there’s no avoiding the need for some kind of “lifecycle api” to apply those required fixups.
Despite the challenges, the benefits to startup are large. A slow-to-start app becomes much faster when restoring from a pre-initialized state. Especially when, as the image shows, multiple instances can share a single initialization by restoring from a common checkpoint.
This has been the state of the art with CRIU investigations for some time. So what’s
new now? A recent pull request
landed in the CRaC repository that allows selecting a new main(String[] args) method
with new application arguments to be executed when restoring a checkpoint.
In the previous example, the application calls jdk.crac.Core.checkpointRestore()
to create the checkpoint and on restore, execution would resume as though returning
from that method call. In this new model, execution continues as though the
checkpointRestore() call was immediately followed by a call to the newly supplied
main class’s main(String[] args) method with the new arguments.

Source code can now reflect the different phases by giving them different entry points into the application. This image shows an application with two explicit phases: an initializer phase and a runtime phase. Each phase gets its own set of application arguments.
The initializer phase can focus on setting up the application, reading any common configuration, and explicitly initializing classes and fields early that would otherwise be lazily initialized in a non-checkpoint run.
The runtime phase can now assume that most of the configuration is done while still being passed application-specific arguments. These arguments can help specialize the restored application for the specific deployment.
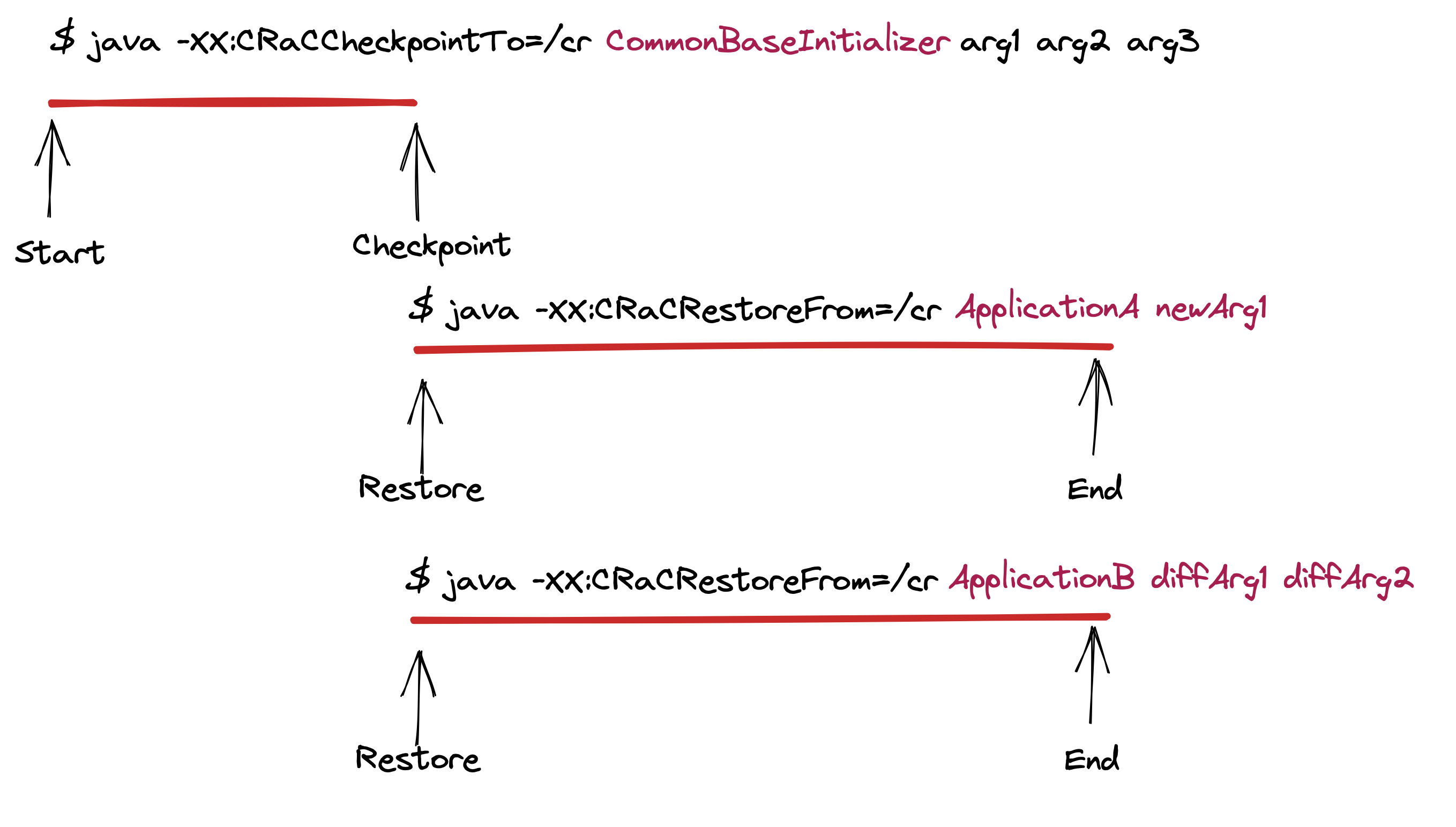
With this latest change to the CRaC project, it is now possible to define a common initializer base that is shared across multiple, different deployments. This common base might initialize the set of libraries common across several microservices, read some company-mandated configuration related to logging or APM services, and initialize shared state allowing each target deployment to start faster, without needing to intermix the common and service-specific code.
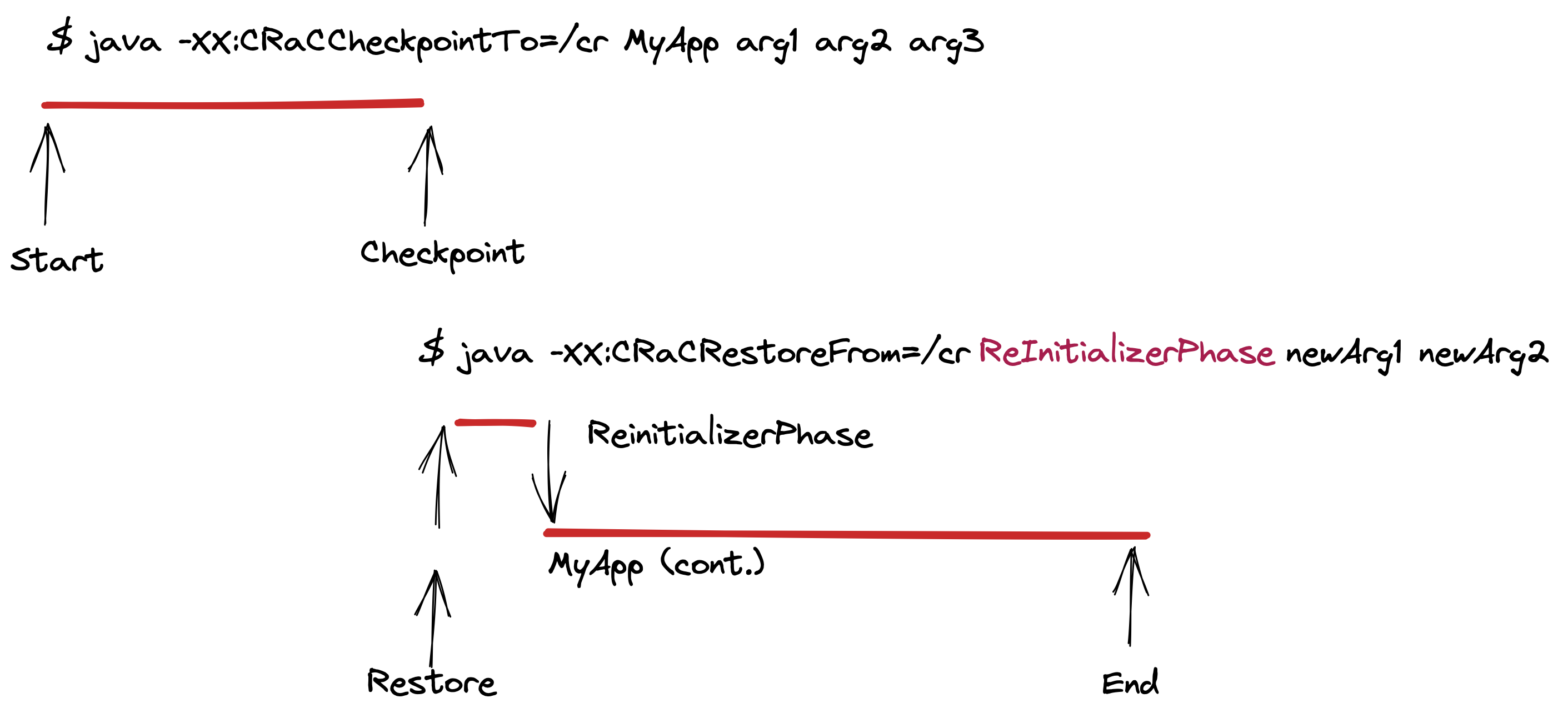
Another phase-aware model injects a “Reinitializer” application into the restore process before continuing to run the original application. The ReInitializerPhase image shows how to use the new class and arguments to reinitialize, or tune, the restored checkpoint for the specific deployment environment.
A use case for this approach would be deploying the same checkpoint across multiple clouds and having a cloud-specific initializer class that runs on restore to tune to the deployment environment. This allows separating AWS-specific logic from Azure or GCP or IBM Cloud-specific logic while still benefiting from the faster startup provided by the checkpoint.
An OpenJ9 example: Security Providers
The OpenJ9 project recognized an issue with Security Providers persisting too much state across the checkpoint/restore.
Their solution? Recognize the pre-checkpoint / post-restore phases need a different
set of providers and use the J9InternalCheckpointHookAPI (aka the Lifecycle api)
to expose different providers in each phase. This is the “reinitializer” pattern
with a different implementation. See the
Add CRIU security hooks
PR for all the details.
Native Java
Does the same technique work for native Java approaches? Probably. To really be sure, we’d need to try to implement it. But there’s nothing in the model that makes me think it wouldn’t work.
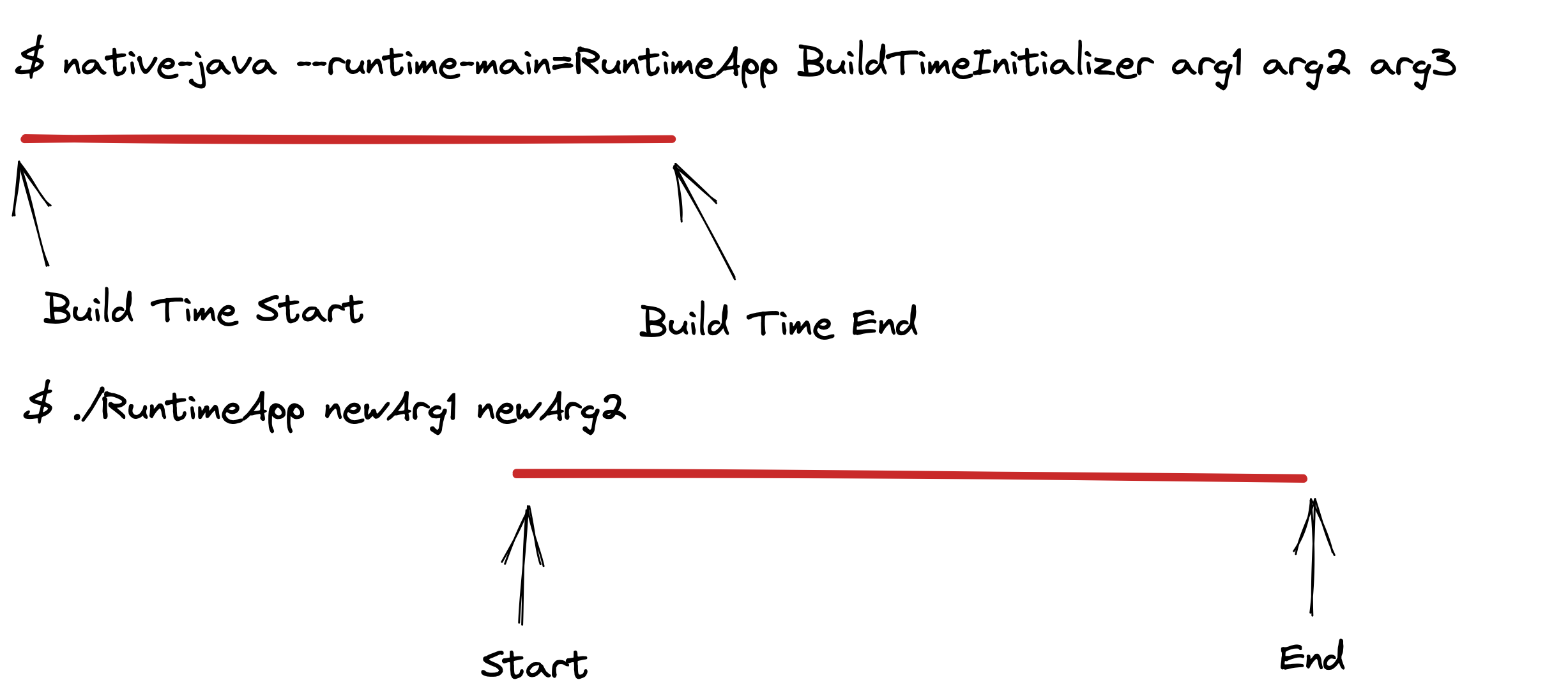
For Native Java, with its closed-world approach and AOT compilation, both the
RuntimeEntryPoint and BuildTimeInitializer, as well as all classes required by both,
would need to be available at build time to create the executable.
The BuildTimeInitializer would be responsible for executing initialization
code, building any singleton objects that can be pre-constructed, reading config
files that don’t depend on runtime values, etc. This would factor the build
time initialization into one entry point.
The RuntimeEntryPoint would provide the main(String[] args) method that would
be invoked at runtime. It would avoid many initialization costs as the previous
phase would have handled those for it.
This starts to make explicit the build time vs runtime initialization that’s been a challenge for Native Java approaches. It doesn’t fully solve the problem but starts to show different options are possible.
Key Takeaway
Expressing the phases directly in the source code exposes new ways of structuring applications so developers, and the runtime, can take better advantage of that awareness.